【PHPライブラリでスクレイピング】PHP Simple HTML DOM Parserで、クラスやID指定で別サイトの内容を取得する方法
| 更新: 2024/02/10 | 3626文字

今回は、以前お仕事で使ったけど没にしたアイデアをご紹介。ライブラリ『PHP Simple HTML DOM Parser』を使って、別サイトのhtmlから情報を取ってみます。『API』『RSS』などを使って情報を取ってくる方法は、いままでいくつか行いましたが、今回はHTML DOM Parserということで、HTMLから取ります。さっそく、内容を確認していきましょう。
目次
PHP Simple HTML DOM Parserとは?
概要や公式・ダウンロードページについて
『htmlをParse(構文解析)』という名前の通り、htmlをパースして要素を取ってきたりできるライブラリです。公式でもアナウンスされている『 supports CSS style selectors to navigate the DOM』というところを読んでみると、『CSSのクラスやID要素をjQueryのような形で指定』というのがあるので、フロント構築やってる場合は、特にイメージがつかみやすいかもしれません。
ライセンスは『MIT License』で、結構自由に使える感じ。公式ドキュメント(英語)やダウンロードページは以下のとおりです。ソフトウェアはフリーでスクレイピング自体も違法性はないけど、『こういうプログラムを使って、許可なく他人のサイトから記事をパクッてきて、自サイトコンテンツに使う』というのは、訴えられる可能性もあるので注意してください。
PHP Simple HTML DOM Parser(公式ページ)
https://simplehtmldom.sourceforge.io/docs/1.9/index.html
(ダウンロードページ/SourceForge)
https://sourceforge.net/projects/simplehtmldom/files/
推奨環境
公式ドキュメントを確認したところ、PHP Simple HTML DOM Parser推奨環境は以下の通りでした。古いPHPでは動かないのでご注意。拡張モジュールやINI設定などもサーバーコントロールパネルやphpinfoファンクションなどで確認してみましょう。
| 要件 | 最低 | 推奨 |
|---|---|---|
| PHP Version | 5.6.0 | 最新安定板 |
| 拡張モジュール | iconv | iconv,mbstring |
| PHP INI設定 | — | allow_url_fopen = 1 |
PHP Simple HTML DOM Parserスクレイピング 事前準備
ライブラリをダウンロードし、任意の場所に
まずはライブラリをダウンロードし、任意のディレクトリに配置。上記のサイトからダウンロードした場合、zip内にマニュアルや例なども入っています。 実際に使うプログラムのファイルは『simple_html_dom.php』です。
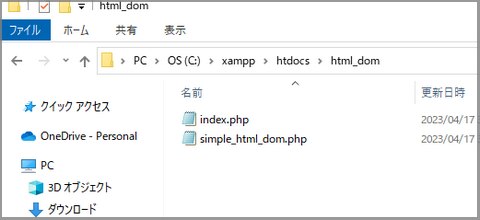 管理人はとりあえずxamppでやってみます。xampp/htdocs/html_dom/フォルダを作り、index.phpとsimple_html_dom.phpはとりあえず同じ階層に。
アドレスはhttp://localhost/html_dom/となります。
管理人はとりあえずxamppでやってみます。xampp/htdocs/html_dom/フォルダを作り、index.phpとsimple_html_dom.phpはとりあえず同じ階層に。
アドレスはhttp://localhost/html_dom/となります。
(扱いやすくなるので推奨)情報を取りたいサイトで、クラスやID指定を行う
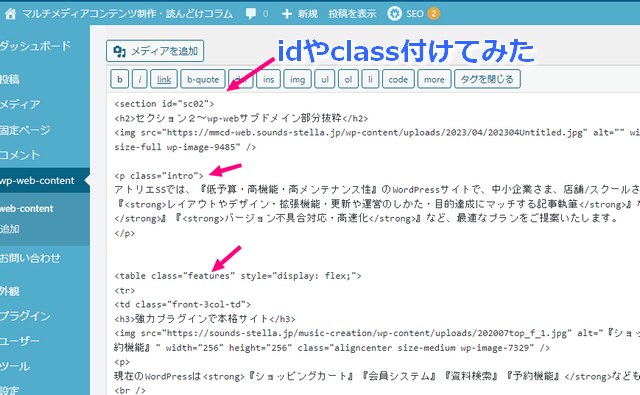 以前、vueなどで要素取ってくるように使った記事(ドメインはこのサイトと同じ/)に、サービス紹介サイトから文章を移植。
Simple HTML DOM Parserで扱いやすくなるように、いくつかクラスやID指定を行いました。というのも、マニュアルによると・・・
以前、vueなどで要素取ってくるように使った記事(ドメインはこのサイトと同じ/)に、サービス紹介サイトから文章を移植。
Simple HTML DOM Parserで扱いやすくなるように、いくつかクラスやID指定を行いました。というのも、マニュアルによると・・・
上記のような、クラスやIDを指定した要素へのアクセスができるからです。
PHP Simple HTML DOM Parser 他サイトのurlからクラスやID指定で、情報を取ってくる方法
HTML DOM objectsの生成のしかた
マニュアルを見た感じだと、要素取得したオブジェクトの生成ファンクションは、2種類あるようです。 ひとつは、文字列を指定した場合の『str_get_html』。もうひとつは、urlやhtmlファイルを指定した場合の『file_get_html』。 書き方は以下の通りです($htmlがオブジェクト)。
また、オブジェクト指向プログラミングでインスタンスを生成し、メソッド呼び出し&値をセット(この書き方でよい?笑)する場合は、以下のような記述になります。
今回の記事では、『ローカル環境から別サイト(よんどけコラム)記事を、url指定で情報取得』という形で行ってみます。
PHP Simple HTML DOM Parser Creating HTML DOM objects(公式マニュアル)
https://simplehtmldom.sourceforge.io/docs/1.9/manual/creating-dom-objects/
コード例と解説
まずはrequire_onceでSimple HTML DOM Parserを読み込みます。file_get_htmlファンクションでurlを指定して、HTML DOM objectsを生成。 そして、findを使って、それぞれの項目をクラスやidで絞り込んで変数に格納していきます( find(‘#sc01 img’,0)は、id=sc01内の画像、0は最初の、という意味)。
階層が浅い場合は、単純に『echo $sc01_img』のようにしても出ますが、項目が配列で戻ってきているときがあり(titleなど)、『echo $title[0]』のように指定して出力しています。
また、通常はhtml内に書かれているタグなども入ってくる(h1やbタグが効いている)ので、単純にテキストだけほしいときは『echo $title[0]->plaintext』にしました。
表示例
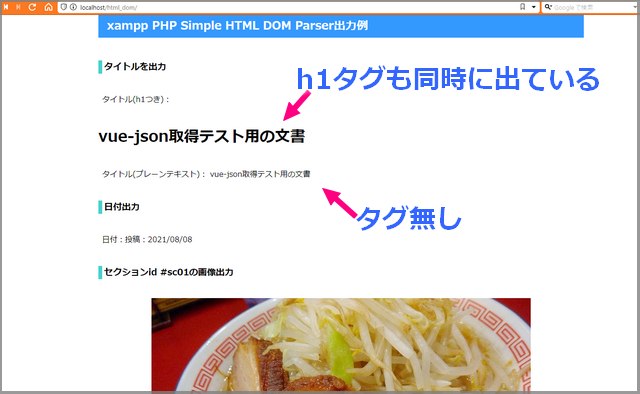 構築はxampp/localhostですが、外部(https://mmcd-web.sounds-stella.jp/)のurlから情報を取得できました。タグが効いているところはそのまま改行したり、文字が大きくなったりしていますね。
構築はxampp/localhostですが、外部(https://mmcd-web.sounds-stella.jp/)のurlから情報を取得できました。タグが効いているところはそのまま改行したり、文字が大きくなったりしていますね。
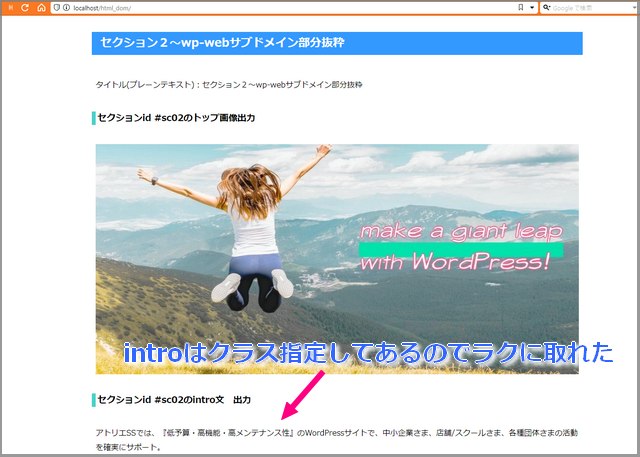 追記したsc02の部分、冒頭文はクラス指定してあるためサクッと取れました。表なども同様に取ることができます。
追記したsc02の部分、冒頭文はクラス指定してあるためサクッと取れました。表なども同様に取ることができます。
あとがき・まとめ
- PHP Simple HTML DOM Parserを使って、外部のサイトからidやクラス指定して、情報を取ってこれる
- id=#sc01内のimgで、最初のもの(0)というような指定もできる
- 階層が深い場合は配列になっているので、『echo $title[0]』のように書く
- タグなしで、単純にテキストだけ出力もできる
まとめると、こんなところでしょうか。今後積極的に使うかはわからないけど、『API』『RSS』のほかに、『html』のような選択肢ができたかと思います(クラス指定してカスタムフィールドみたいに使うとかも)。